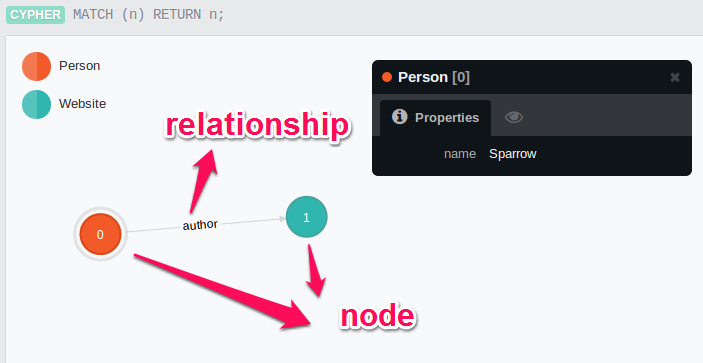
neo4j是一種圖形資料庫,同時也是nosql的一種,每筆資料為一個node,在node上可以定義label,類似於其他資料庫的table/collection。假設有個Person的collection,要定義Person與Person之間的關係,勢必得額外定義一個collection或者field,去描述Person與Person之間的關係,但是neo4j並不需要額外的collection或field,只要定義好Person這個label,當關係產生時,在額外描述Person與Person之間關係(relationship)為何,換句話說一開始建立Person的node時,並不需要定義Person與Person的關係。
舉例來說,如果今天Tom和Jack就讀同一個學校同一個班級,現在的關係是classmate,當熟識之後,這時關係可能是friend,這時就必須建立friend的關聯(朋友本身是雙向的,這邊以單向為例)。
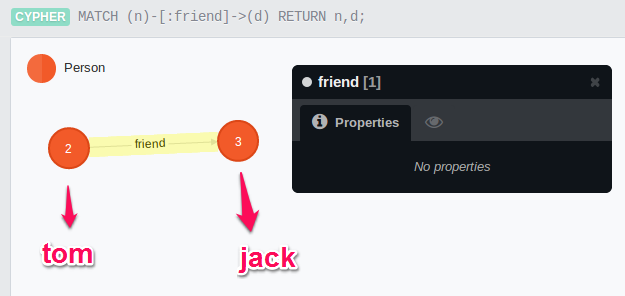
在neo4j建立Person和type為friend關聯的語法會如下:1
CREATE (Tom {name:"tom"})-[:friend]->(Jack {name:"jack"});
如果單純的建立relationship,需先抓取tom和jack兩個人:
1 | MATCH (tom), (jack) |
Neo4j中的Nodes
在neo4j中的node,可以寫成以下幾種方式:
(a)(a:Person)指定label為Person()以匿名的方式
括號中的a,如同(),唯一不同之處,可以在MATCH時,透過a來做比對,而透過:Person這種指定label的方式,可以明確要查詢的label名稱,同樣也會增加query的效率。
Neo4j中的Relationships
在neo4j中的關係(relationship)表示方式,以中括弧[]作為表示,可以參考以下幾種:
(a)-[r]->(m)定義a點到m點之間的關係(a)-[:ACTED_IN]->(m)定義a點到m點之間的關係,其中定義:ACTED_IN的label,為描述a與m之間的關係
Labels
不管是node或relationship都可以定義一個甚至多個label。下方以定義一個label為例:
(a:Person)(a:Person {name:"Keanu Reeves"})(a:Person)-[:ACTED_IN]->(m:Movie)
CREATE
建立一個node,label為Person,{name:"tom"}為node被建立的資料。最前面的tom只是一個變數,在這個語法中並不會被使用到。
1 | CREATE (tom:Person {name:"tom"}); |
建立classmate的relationship,其中classmate在relationship中,被稱為type。
1 | CREATE (Tom {name:"tom"})-[:classmate]->(Jack {name:"jack"}); |
如果要描述關係的其他屬性,例如什麼時間點成為classmate,可在關係中附加資料。1
CREATE (Tom {name:"tom"})-[:classmate {start_date:"2012/01/05"}]->(Jack {name:"jack"});
CREATE INDEX
依照name去建立index,在search中效率會提昇許多。1
CREATE INDEX ON :Person(name);
MATCH
如果要回傳所有node筆數的資料如下。
1 | MATCH (p) RETURN p; |
找出有建立relationship的node,可以這樣寫。
1 | MATCH (t)-->(j) RETURN t,j; |
若是要依照type去search,例如要找是friend關係的,列出Person的name。
1 | MATCH (t)-[:friend]->(j) RETURN t.name,j.name; |
查詢Person與Person之間的關係,可以透過type這個function。
1 | MATCH (t)-[r]->(j) RETURN t.name, type( r ),j.name; |
WHERE
要search某個屬性,可透過where,例如找name是tom的人。
1 | MATCH (t) |
同樣的查詢條件,也可直接透過下面這種方式,寫法更為簡短。1
2MATCH (t {name:"tom"})
RETURN t;
Order
依照出生日期作排序。
1 | MATCH (a:Person) |
Limit and Skip
limit指的是query後的資料要抓幾筆,而skip則是從第幾筆開始抓取。
從第10筆開始抓取,最多抓10筆。1
2
3
4MATCH (a)
RETURN a.name
SKIP 10
LIMIT 10;
nodes
在path中,回傳所有節點。1
MATCH p = (t)-[:friend]->(j) RETURN nodes(p);
rels
在path中,回傳節點對應的關係。1
MATCH p = (t)-[:friend]->(j) RETURN rels(p);
DISTINCT
假設有兩個Person的名稱為相同,此時要列出所有Person的name,這時可透過DISTINCT把相同name的都過濾掉,
1 | MATCH (p:Person) |
SET
SET可用於node和relationship、label的屬性修改。
例如例如例如例如設定movie釋出時間。
1 | MATCH (movie:Movie) |
如果要加入一個label,可直接使用SET。1
2
3
4MATCH (movie:Movie)
WHERE movie.title="Mystic River"
SET movie:Movie
RETURN movie
REMOVE
移除label,直接使用REMOVE即可。
1 | MATCH (movie:Movie) |
DELETE
刪除node或relationship。
刪除一個節點。1
2MATCH (n { name: 'Peter' })
DELETE n
MATCH Depth Relationship
a到b所包含多個relationship。
1 | (a)-[*]->(b) |
a到b包含1~3個relationship,也就是中間含有0~3個node。1
(a)-[*1..4]->(b)
shortestPath
會自動找出最短路徑,也就是假設a到b點,可能有10個路徑,只會傳一個最短路徑。
1 | MATCH (keanu:Person {name:"Keanu Reeves"}), |
extract
可在extract執行運算,之後的結果會回傳一個list。寫法包括以下2種:
- extract(n in nodes(path) | n.name)
- [ x in coll | expr ]
1 | extract(x in [1,2,3] | x*x) |
取得keanu知道(relationship)kevin的最短路徑,其中[1..-1]則捨棄list的第一個和最後一個值。1
2
3
4MATCH (keanu:Person {name:"Keanu Reeves"}),
(kevin:Person {name:"Kevin Bacon"})
MATCH p=shortestPath((keanu)-[:KNOWS*]->(kevin))
RETURN [ n in nodes(p)[1..-1] | n.name ];
neo4j可用的function可以參考官方文件。另外可以參考官方的語法對照表和官方的online tutorial,對於neo4j學習會有很大幫助。